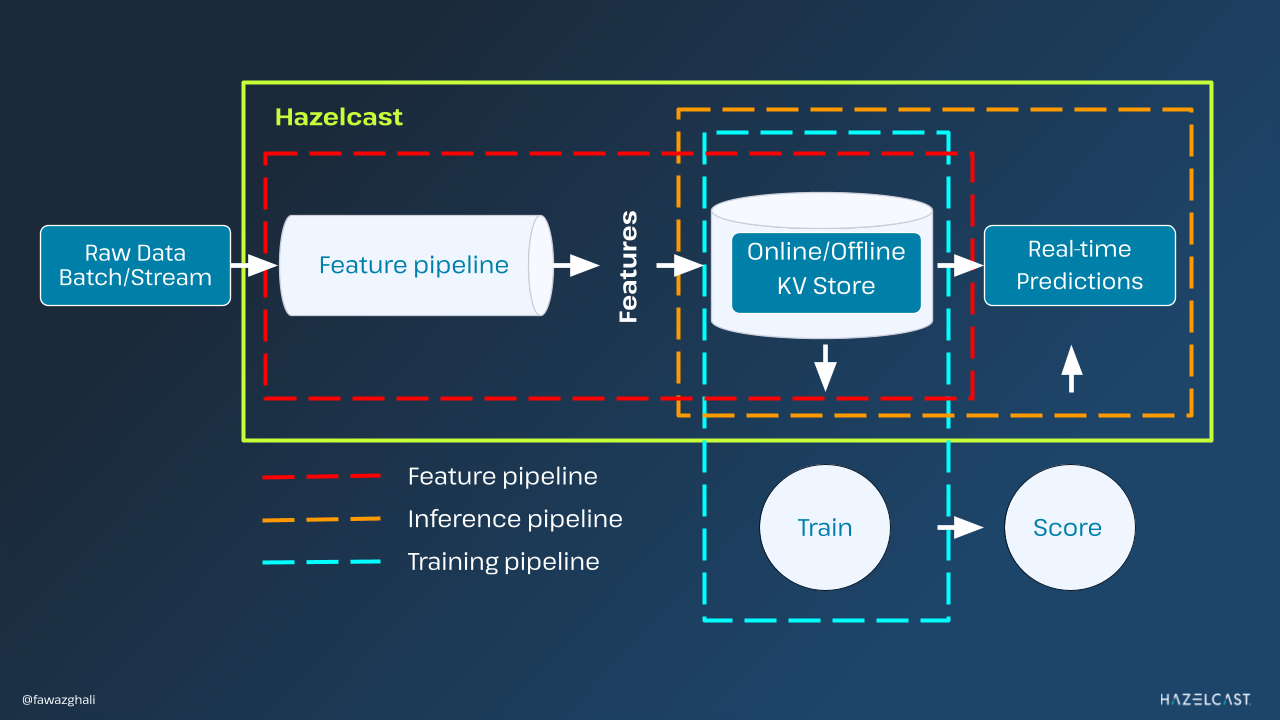
Hazelcast Platform offers a unique advantage over other solutions offering in-memory and stream processing separately. It combines both technologies into a single runtime, which results in a seamless developer experience. All API calls can be made within the Hazelcast namespace, simplifying the development process. The real benefit of this implementation becomes evident when data is loaded into Hazelcast Platform for processing. The ability to process data, which is commonly referred to as building data pipelines, is crucial.
Data Pipeline
A data pipeline (also called a pipeline) is a series of steps for processing data consisting of three elements:
- One or more sources: Where does the data come from?
- Processing stages: What actions are taken against the data?
- At least one sink: Where are data results sent from the last processing stage?
Pipelines are an essential component in the modern data processing ecosystem. They are mainly used to move data from one location to another while processing it in between. Pipelines provide a seamless way to process data stored in one location and send the result to another, such as from a data lake to an analytics database or into a payment processing system.
One of the most significant benefits of using pipelines is that they can be used to process data without manual intervention, which saves time and reduces the likelihood of errors. Additionally, pipelines can automate the movement and processing of data, resulting in a more streamlined and efficient workflow.
Moreover, pipelines can also be used to process data multiple times and send it to different locations. For example, the same source and sink can be used so that the pipeline only processes data. This can be useful to avoid unnecessary data duplication and processing.
Batch and Stream Processing
Depending on the data source, pipelines can be used for the following patterns:
- Batch processing: Processes a finite amount of static data for repetitive tasks such as daily reports.
- Stream processing: Processes an endless stream of data, such as events, to deliver results as the data is generated.
What are transforms and how to use them?
Hazelcast Platform is a distributed computing platform offering a range of data processing transformations. Depending on the user’s specific needs, these transforms can be used to analyze, filter, aggregate, or manipulate data sets.
Some available transforms in Hazelcast Platform include map, filter, flatmap, aggregate, and group-by. The map transform transforms each element in a data set by applying a user-defined function. The filter transform is used to select elements that meet a certain condition. The flatmap transform transforms each element in a data set into zero or more elements. The aggregate transform performs calculations on a data set and returns a single result. The group-by-transform groups elements in a data set based on a specific attribute.
Learning how to use these transforms can help improve data processing efficiency and enable users to extract valuable insights from large data sets. By leveraging transforms, users can better understand their data and make more informed decisions.
Hazelcast Platform transforms are organized into two categories by state. Stateless and stateful concepts in programming refer to how a system or program manages and stores information.
Stateless
A stateless system or program does not track data between requests or sessions. Each request is processed independently, and the system does not rely on any information from previous requests. Stateless systems are simpler and more scalable, but they may not be suitable for certain applications that require persistent data.
Stateless transforms do not have any notion of state, meaning that all items must be processed independently of previous items.
These methods transform the input into the correct shape that further, more complex ones require. The key feature of these transforms is that they do not have side effects and treat each item in isolation.
Stateful
On the other hand, a stateful system or program maintains information or state between requests or sessions. This means the system relies on information from previous requests to process new ones. For example, an e-commerce website may store items in a user’s shopping cart between requests. Stateful systems are more complex and less scalable, but they are often necessary for applications that require persistent data, such as banking or healthcare systems.
Stateful transforms accumulate data, and the output depends on previously encountered items.
For example, using stateful transforms, one could count how many items have been encountered in a stream and emit the current count with every new item. To do so, Hazelcast Platform maintains a current state of the number of total items encountered so far.
Regarding maintaining state, it’s important to note the difference between streaming and batch jobs. Windowing is only applicable to streaming jobs because it involves an element of time. On the other hand, one-time aggregation over the entire dataset is only possible in batch pipelines.
Deep dive into “mapUsing…” transforms
The “mapUsing…” transforms are a specific subset of stateless transforms. Developers can use these transforms to perform complex data manipulations, such as converting data to different formats, combining data from multiple sources, and performing calculations on data. This flexibility makes “mapUsing…” transforms an essential tool for developers who need to manipulate data in various ways.
Overall, these transforms are a valuable tool for any developer who needs to manipulate data flexibly and efficiently. With their ability to customize data mappings, developers can easily create complex transformations that meet specific requirements, making them a popular choice among developers.
Java Lambda Expressions
A developer must understand Java Lambda Expressions to utilize transforms fully.
Java Lambda Expressions are a powerful feature introduced in Java 8 that allows developers to write more concise and readable code. A Lambda Expression is a short code block representing a single-method interface.
Here’s a brief tutorial on how to use Lambda Expressions in Java:
- Syntax: The basic syntax of a Lambda Expression is as follows:
-
(argument) -> (body)
For example:
(x, y) -> x + y
- Interfaces: Lambda Expressions can only be used with interfaces with a single abstract method, also known as functional interfaces. For example, the java.util.function package contains several built-in functional interfaces, such as Predicate, Consumer, and Supplier.
- Functional Interfaces: To use a Lambda Expression, developers need to create an instance of a functional interface that matches the Lambda Expression signature. For example, if a functional interface with a single method takes two arguments and returns a Boolean, a developer can use a Lambda Expression like so:
Predicate<Integer> isEven = (n) -> (n % 2 == 0);
- Type Inference: In Java 8, a developer can use type inference to let the compiler deduce the type of the Lambda Expression parameters. For example, instead of writing:
Predicate<Integer> isEven = (Integer n) -> (n % 2 == 0);
A developer can write:
Predicate<Integer> isEven = (n) -> (n % 2 == 0);
- Method References: Lambda Expressions can also be used with method references, which allow a developer to refer to an existing method by its name instead of writing a Lambda Expression that calls the method. For example:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie"); names.forEach(System.out::println);
mapUsingIMap
The mapUsingIMap transform is an advanced feature that allows you to retrieve each incoming item efficiently from its corresponding IMap1. With this transformation, you can seamlessly combine the lookup result with the input item, providing a detailed and comprehensive view of your data. This feature is especially useful for complex data transformations or large datasets. By utilizing this transform, you can simplify your data processing pipeline and improve the overall efficiency of your workflow. Experience the benefits of this powerful feature today and take your data processing to the next level.
StreamStage<Order> orders = pipeline .readFrom(KafkaSources.kafka(.., "orders")) .withoutTimestamps();StreamStage<OrderDetails> details = orders.mapUsingIMap("products", order -> order.getProductId(), (order, product) -> new OrderDetails(order, product));
In the code snippet above, line 1 declares the “orders” object that receives the Kafka message, which we can assume is a new order. On line 4, the “details” object accesses the product information for the order using the ‘orders.mapUsingIMap(“products”,’. On line 5, the transform retrieves the specific product data by matching the “order” with the “order.getProductId(),”. Line 6 uses the “order” and “product” objects to create a new OrderDetails object.
* IMap – Distributed maps, also known as maps or IMaps, are a type of data structure that store key-value pairs and are designed to be partitioned across a cluster. This means that each node in the cluster stores a portion of the data rather than the data being stored on a single machine. This approach provides several benefits, including improved scalability and fault tolerance.
mapUsingReplicatedMap
The mapUsingReplicatedMap transform is a data processing technique that uses a ReplicatedMap2 instead of an IMap to store and process data. ReplicatedMap2 is a distributed data structure that provides high availability, fault tolerance, and scalability by replicating data across multiple nodes. It is like the IMap data structure but with additional features such as automatic data replication, conflict resolution, and event listeners. The mapUsingReplicatedMap transform is particularly useful when data consistency and availability are critical, such as in distributed systems, real-time applications, and high-traffic websites. Using ReplicatedMap2 instead of IMap, the transform ensures that data is always available and consistent, even in node failures or network outages.
StreamStage<Order> orders = pipeline .readFrom(KafkaSources.kafka(.., "orders")) .withoutTimestamps();StreamStage<OrderDetails> details = orders.mapUsingReplicatedMap("products", order -> order.getProductId(), (order, product) -> new OrderDetails(order, product));
For a detailed breakdown of the code snippet above, see mapUsingIMap.
* ReplicatedMap – A Replicated Map is a distributed data structure that stores key-value pairs in a cluster of computers. The data stored in this structure is replicated to all cluster members, ensuring that all nodes have an identical copy of the data. This replication provides high-speed access to fully replicated entries, as any node in the cluster can respond to a read request, eliminating the need for communication with other nodes. Additionally, the replication of data ensures that the system is highly available, as a node failure does not cause data loss and can be easily recovered by replicating the data from the surviving nodes.
mapUsingService
The mapUsingService transform is a versatile function that takes an input and applies a mapping using a service object, an external HTTP-based service, or a library loaded and initialized during runtime, like a machine learning model.
This function is particularly useful when you need to perform complex mappings that would require a significant amount of manual effort. By leveraging the capabilities of a service object, you can streamline your data transformation process and save valuable time and resources.
Using mapUsingService allows you to take advantage of the latest technologies and innovations in data mapping. For example, you can use a machine learning model to automatically generate mappings based on patterns in your data, which can lead to more accurate and reliable results.
The service itself is defined through a ServiceFactory object. The main difference between this operator and a simple map is that the service is initialized once per job. This makes it useful for calling out to heavy-weight objects that are expensive to initialize (such as HTTP connections).
Let’s imagine an HTTP service that returns details for a product and that we have wrapped this service in a ProductService class:
interface ProductService { ProductDetails getDetails(int productId);}
In the code snippet above, line 1 declares an interface “ProductService.” Line 2 declares a method “getDetails” that takes in an integer for “productId” which returns the “ProductDetails” object.
We can then create a shared service factory as follows:
StreamStage<Order> orders = pipeline .readFrom(KafkaSources.kafka(.., "orders")) .withoutTimestamps();ServiceFactory<?, ProductService> productService = ServiceFactories .sharedService(ctx -> new ProductService(url)) .toNonCooperative();
In the code snippet above, line 1 declares the “orders” object populated from a Kafka pipeline containing order messages (lines 2-3). Line 4 declares a “productService” object that returns ServiceFactory, which implements the ProductService interface.
“Shared” means that the service is thread-safe and can be called from multiple threads, so Hazelcast Platform will create just one instance on each member and share it among the parallel tasks.
We also declared the service “non-cooperative” because it blocks HTTP calls. A developer must do this to ensure the performance of the pipeline and all the jobs running on the cluster.
We can then perform a lookup on this service for each incoming order:
StreamStage<OrderDetails> orderDetails = orders.mapUsingService(productService, (service, order) -> { ProductDetails productDetails = service.getDetails(order.getProductId); return new OrderDetails(order, orderDetails); });
In the code snippet above, line 1 declares the “orderDetails” variable populated from the “orders” object in the previous code snippet via the “mapUsingService” method. On line 2, the “service” and “order” variables map to the “ProductService” and “Order” objects, respectively. On line 3, the “productDetails” object is populated with “ProductDetails” data from the “service” based on the corresponding “order.getProductId”. Line 4 returns the new “OrderDetails” object with the “order” and “orderDetails” variables populated.
mapUsingServiceAsync
The mapUsingServiceAsync transform is identical to mapUsingService with one important distinction: the service, in this case, supports asynchronous calls, which are compatible with cooperative concurrency and don’t need extra threads. It also means we can simultaneously have multiple requests in flight to maximize throughput. Instead of the mapped value, this transform expects the user to supply a CompletableFuture<T> as the return value, which will be completed at some later time. CompletableFuture is a class introduced in Java 8 that allows us to write asynchronous, non-blocking code. It is a powerful tool to help us write more efficient and responsive code.
For example, if we extend the previous ProductService as follows:
interface ProductService { ProductDetails getDetails(int productId); CompletableFuture<ProductDetails> getDetailsAsync(int productId);}
In the code snippet above, line 1 declares an interface “ProductService.” Line 2 declares a method “getDetails” that takes an integer parameter for “productId,” which returns the “ProductDetails” object. Line 3 declares a method “getDetailsAsync” that takes an integer parameter for “productId,” which returns the “CompletableFuture<ProductDetails>” object.
We still create the shared service factory as before:
StreamStage<Order> orders = pipeline .readFrom(KafkaSources.kafka(.., "orders")) .withoutTimestamps();ServiceFactory<?, ProductService> productService = ServiceFactories .sharedService(ctx -> new ProductService(url));
In the code snippet above, line 1 declares the “orders” object populated from a Kafka pipeline containing order messages (lines 2-3). Line 4 declares a “productService” object that returns ServiceFactory, which implements the ProductService interface.
The lookup instead becomes async, and note that the transform also expects to return.
StreamStage<OrderDetails> orderDetails = orders.mapUsingServiceAsync(productService, (service, order) -> { CompletableFuture<ProductDetails> futureProductDetails = service.getDetailsAsync(order.getProductId); return futureProductDetails.thenApply(orderDetails -> new OrderDetails(order, orderDetails)); });
In the code snippet above, line 1 declares the “orderDetails” variable populated from the “orders” object in the previous code snippet via the “mapUsingServiceAsync” method. On line 2, the “service” and “order” variables map to the “ProductService” and “Order” objects, respectively. On line 3, the “futureProductDetails” variable is populated with “ProductDetails” data from the “service” based on the corresponding “order.getProductId”. Line 4 returns the new “OrderDetails” object with the “order” and ”orderDetails” variables populated.
The main advantage of async communication is that we can simultaneously have many invocations to the service in flight, resulting in better throughput.
mapUsingServiceAsyncBatched
The mapUsingServiceAsyncBatched transform is like the previous one. Still, instead of sending one request at a time, we can send in so-called “smart batches” (for a more in-depth look at the internals of the Hazelast stream processing engine, see Cooperative Multithreading3). Hazelcast Platform will automatically group items as they come, allowing us to send requests in batches. For example, this can be very efficient for a remote service, where instead of one roundtrip per request, it can send them in groups to maximize throughput.
* Cooperative Multithreading – Hazelcast Platform doesn’t start a new thread for each concurrent task. The execution of a task can be suspended purely on the Java level. The underlying thread executes, returning control to the framework code that manages many coroutines on a single worker thread. We use this design to maximize CPU utilization.
If we would extend our ProductService as follows:
interface ProductService { ProductDetails getDetails(int productId); CompletableFuture<ProductDetails> getDetailsAsync(int productId); CompletableFuture<List<ProductDetails>> getAllDetailsAsync(List<Integer> productIds);}
In the code snippet above, line 1 declares an interface “ProductService.” Line 2 declares a method “getDetails” that takes an integer parameter for “productId,” which returns the “ProductDetails” object. Line 3 declares a method “getDetailsAsync” that takes an integer parameter for “productId,” which returns the “CompletableFuture<ProductDetails>” object. Line 4 declares a method “getAllDetailsAsync” that takes a List<Integer> parameter for “productIds,” which returns the “CompletableFuture<List<ProductDetails>>” object.
We still create the shared service factory as before:
StreamStage<Order> orderList = pipeline .readFrom(KafkaSources.kafka(.., "orders")) .withoutTimestamps();ServiceFactory<?, ProductService> productService = ServiceFactories .sharedService(ctx -> new ProductService(url));
For a detailed breakdown of the code snippet above, see mapUsingServiceAsync.
We can then rewrite the transform as:
StreamStage<OrderDetails> orderDetails = orders.mapUsingServiceAsyncBatched(productService, (service, orderList) -> { List<Integer> productIds = orderList .stream() .map(o -> o.getProductId()) .collect(Collectors.toList()) CompletableFuture<List<ProductDetails>> futureProductDetails = service .getDetailsAsync(order.getProductId()); return futureProductDetails.thenApply(productDetailsList -> { List<OrderDetails> orderDetailsList = new ArrayList<>(); for (int i = 0; i < orderList; i++) { new OrderDetails(order.get(i), productDetailsList.get(i))) } }; });})
In the code snippet above, line 1 declares the “orderDetails” variable populated from the “orders” object in the previous code snippet via the “mapUsingServiceAsyncBatched” method. On line 2, the “service” and “orderList” variables map to the “ProductService” and “Order” objects, respectively. On line 3, the “productIds” variable is populated from “orderList.” Line 7, the “futureProductDetails” variable is populated from the “service.getDetailsAsync” method. Line 9, the “futureProductDetails,” a CompletableFuture<List<ProductDetails>> object, returns the new “OrderDetails” object by mapping the “order” and “productDetailsList.”
Combining the results will require additional code. However, if the service can batch efficiently, this approach should improve throughput.
mapUsingPython
With the mapUsingPython transform, you can leverage the power of Python to unlock insights from your data and accelerate your data-driven decision-making process. The Hazelcast Platform can call Python code to execute a mapping step in the pipeline. To do so, the Hazelcast Platform servers must run on Linux or Mac operating systems with Python installed. Additionally, the hazelcast-jet-python module must be deployed on the classpath by being present in the lib directory. It is important to note that Hazelcast Platform supports Python versions 3.5-3.7.
The developer is expected to define a function, conventionally named transform_list(input_list), that takes a list of strings and returns a list whose items match positionally one-to-one with the input list. Hazelcast Platform will call this function with batches of items the Python mapping stage receives. If necessary, the developer can also use a custom name for the transforming function.
Internally, the Hazelcast Platform launches Python processes that execute the function. It launches as many of them as requested by the localParallelism setting on the Python pipeline stage. It prepares a local virtual Python environment for the processes to run in, and they communicate with it over the loopback network interface using a bidirectional streaming gRPC call.
Some simple Python work that fits into a single file can tell Hazelcast Platform just the name of that file, which is assumed to be a Python module file that declares transform_list:
StreamStage<String> sourceStage = sourceStage();StreamStage<String> pythonMapped = sourceStage.apply(PythonTransforms.mapUsingPython( new PythonServiceConfig().setHandlerFile("path/to/handler.py")));
In the code snippet above, line 1 declares the “sourceStage” variable. Line 2 declares the “pythonMapped” variable that is set to the “sourceStage” object with the “PythonTransforms.mapUsingPython” method. Line 3 creates a new “PythonServiceConfig” object and sets the path to the Python file to run.
And here’s an example of handler.py:
def transform_list(input_list): return ['reply-' + item for item in input_list]
In the code snippet above, line 1 declares the Python function “transform_list,” which takes “input_list” as a parameter. After line 1, the developer would add Python code to process the data passed to the function via “input_list.” Line 2 shows a simple return statement to Hazelcast.
An entire Python project that a developer wants to use from Hazelcast Platform, name its base directory, and Hazelcast Platform will upload all of it (recursively) to the cluster as a part of the submitted job. In this case, a developer must also name the Python module that declares transform_list:
StreamStage<String> sourceStage = sourceStage();StreamStage<String> pythonMapped = sourceStage.apply(PythonTransforms.mapUsingPython( new PythonServiceConfig().setBaseDir("path/to/python_project") .setHandlerModule("pipeline_handler")));
In the code snippet above, line 1 declares the “sourceStage” variable. Line 2 declares the “pythonMapped” variable that is set to the “sourceStage” object with the “PythonTransforms.mapUsingPython” method. Line 3 creates a new “PythonServiceConfig” object and sets the path to the Python file to run. Line 4 sets the Python file (does not include the “.py” extension).
Python code often uses non-standard libraries. Hazelcast Platform recognizes the requirements.txt file to satisfy all listed requirements.
Hazelcast Platform supports two bash scripts, init.sh and cleanup.sh, that can be used for a job’s initialization and cleanup phases. These scripts run once per job, regardless of the parallelism of the Python stage, and they execute within an already activated virtual environment context.
Getting requirements.txt working in production back-end environments where public internet access is unavailable can be challenging. To overcome this, a developer can pre-install all the requirements to the global or user-local Python environment on all Hazelcast Platform servers. Alternatively, a developer can take full control by writing logic in init.sh that installs the dependencies in the local virtual environment. For instance, they can utilize pip with the –find_links option.